DELO: Deep Evidential LiDAR Odometry using Partial Optimal Transport
Sk Aziz Ali1 · Djamila Aouada2 · Gerd Reis1 · Didier Stricker1 ·

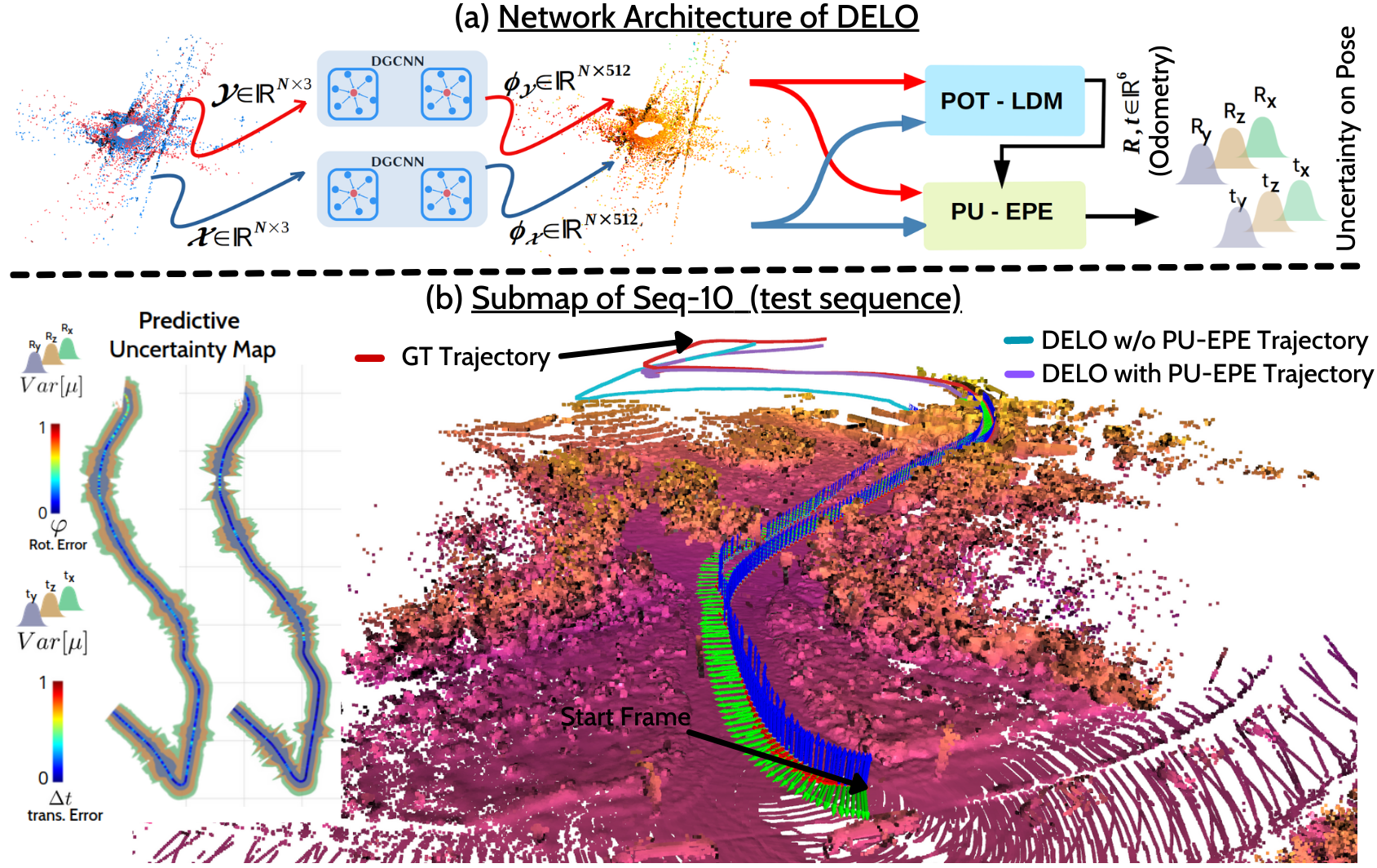
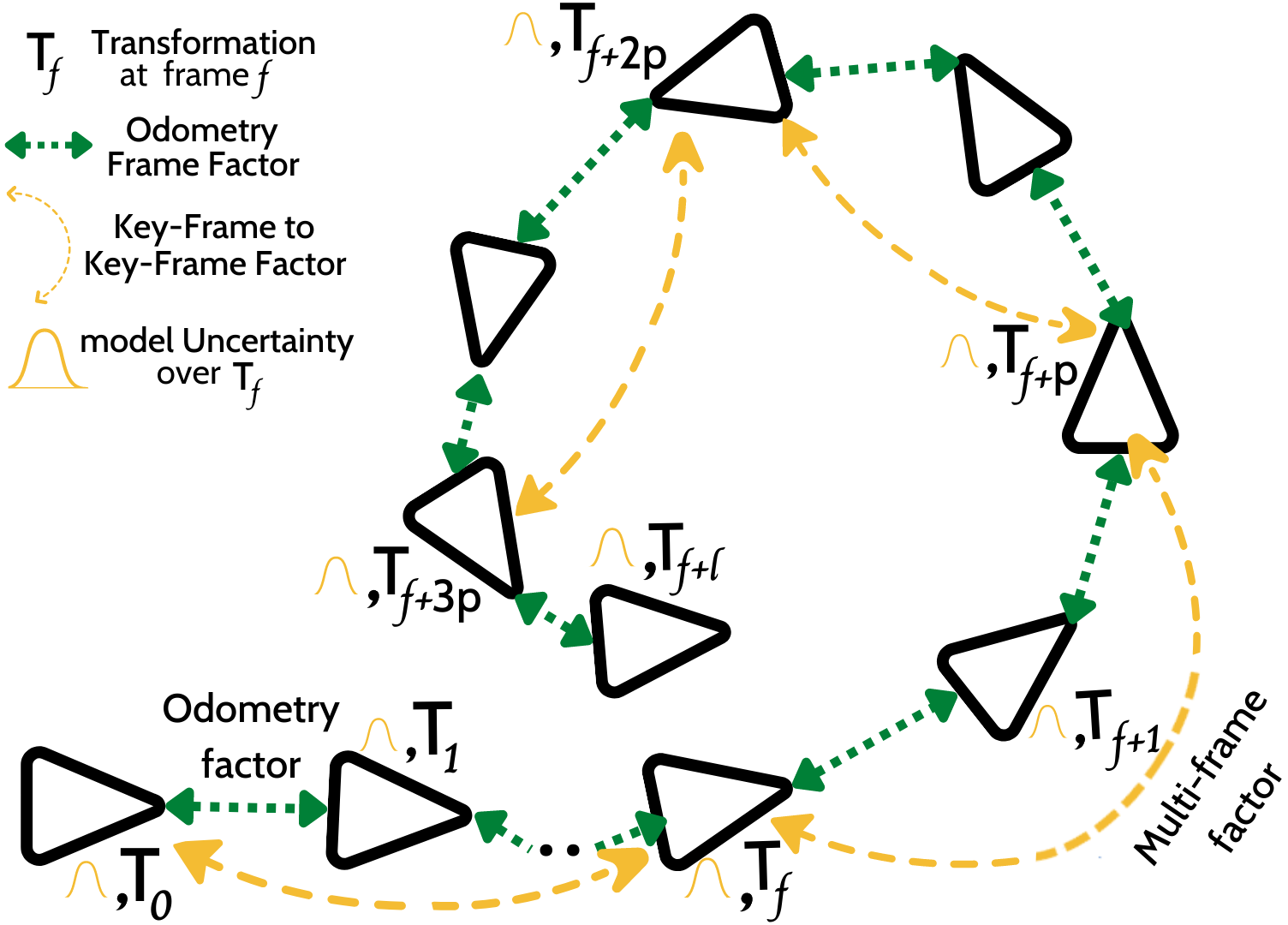
Given sequential point clouds of input frames, DELO applies DGCNN as backbone encoder to obtain a point-wise feature embedding \(\phi_{\mathcal{Y}}\) and \(\phi_{\mathcal{X}}\). Then it simultaneously aligns the frames using the Partial Optimal Transport plan for LiDAR Descriptor Matching (POT-LDM), and estimates the Predictive Uncertainty for the Evidential Pose Estimation (PU-EPE). With the help of PU estimates pose-graphs are refined. (b) This part depicts a sub-map between frame 1 to 300 of KITTI test sequence-10 with all outputs from DELO.
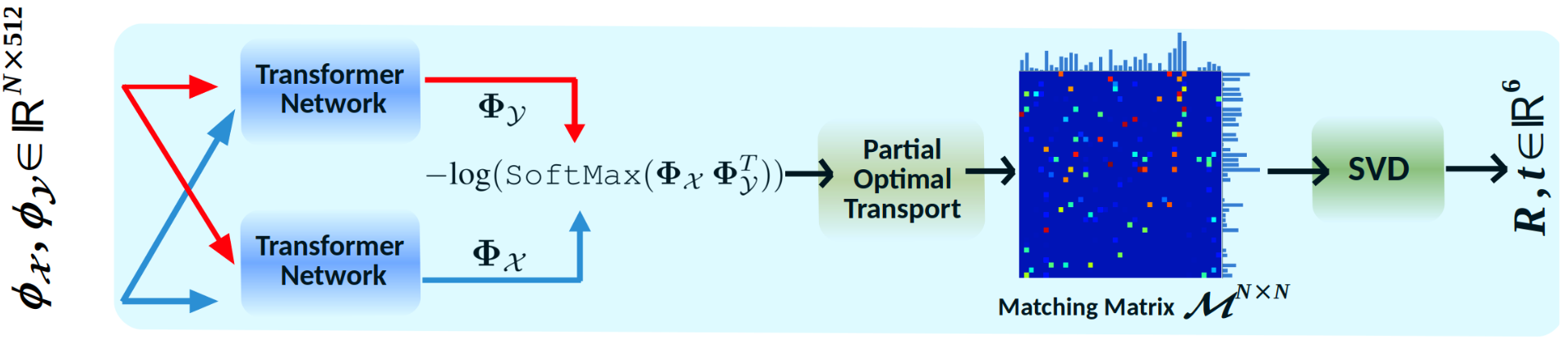
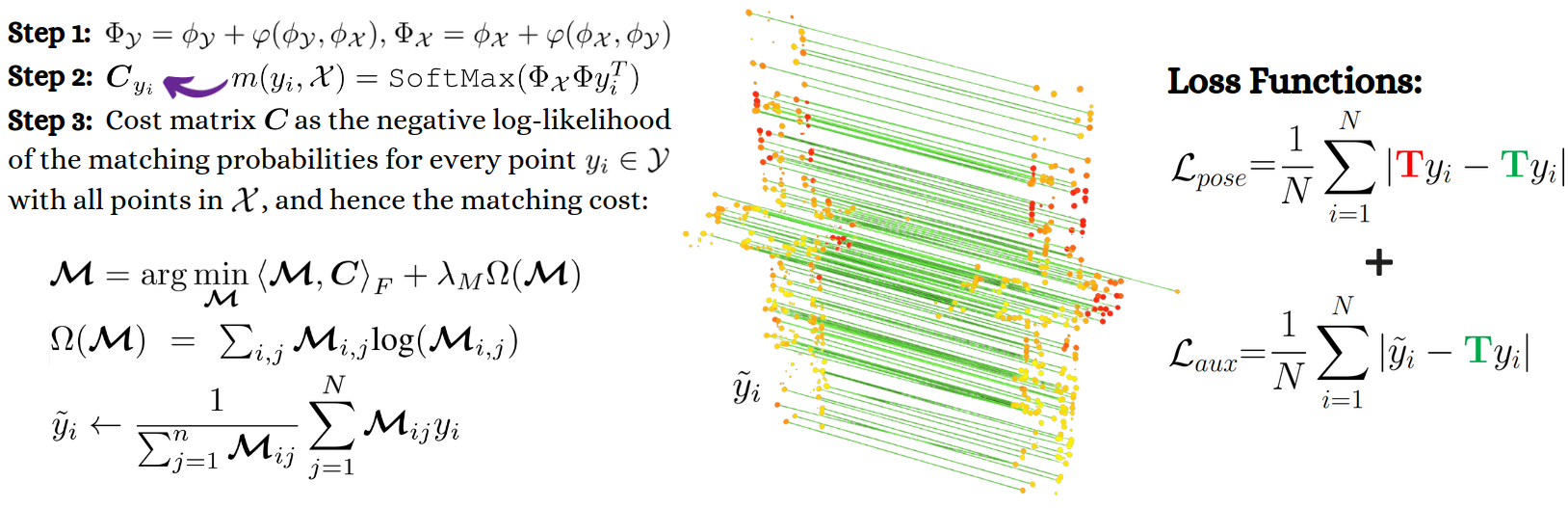
The proposed DELO applies frame-to-frame LiDAR descriptor matching (LDM) using partial optimal transport (POT) [POT, Optimal transport, old and new, Sinkhorn OT]
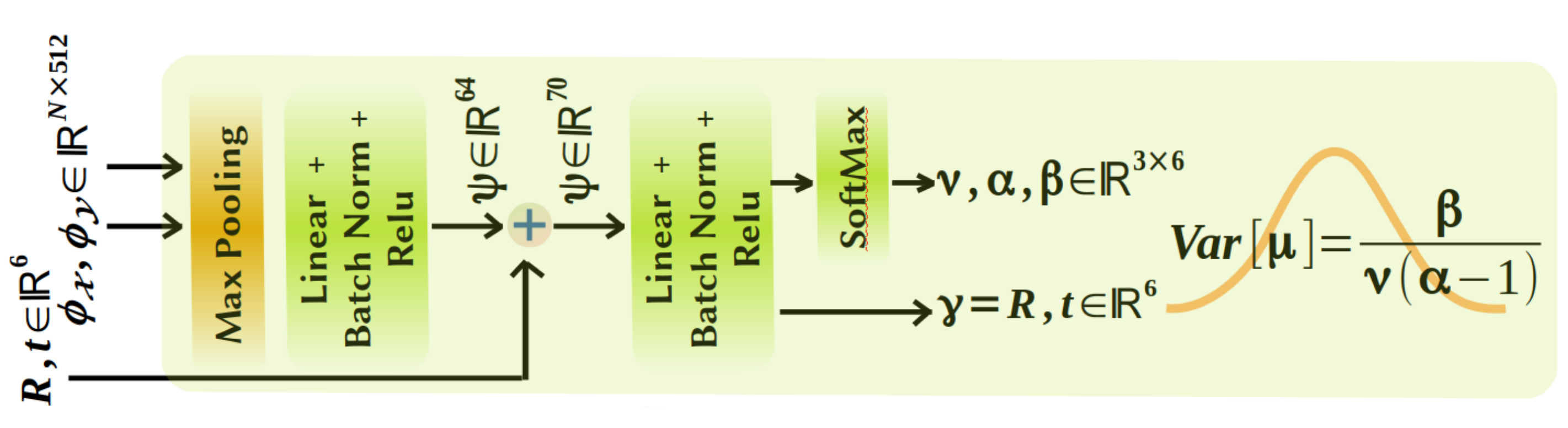
Deep Evidential LiDAR Odometry estimation network is comprised of three components:

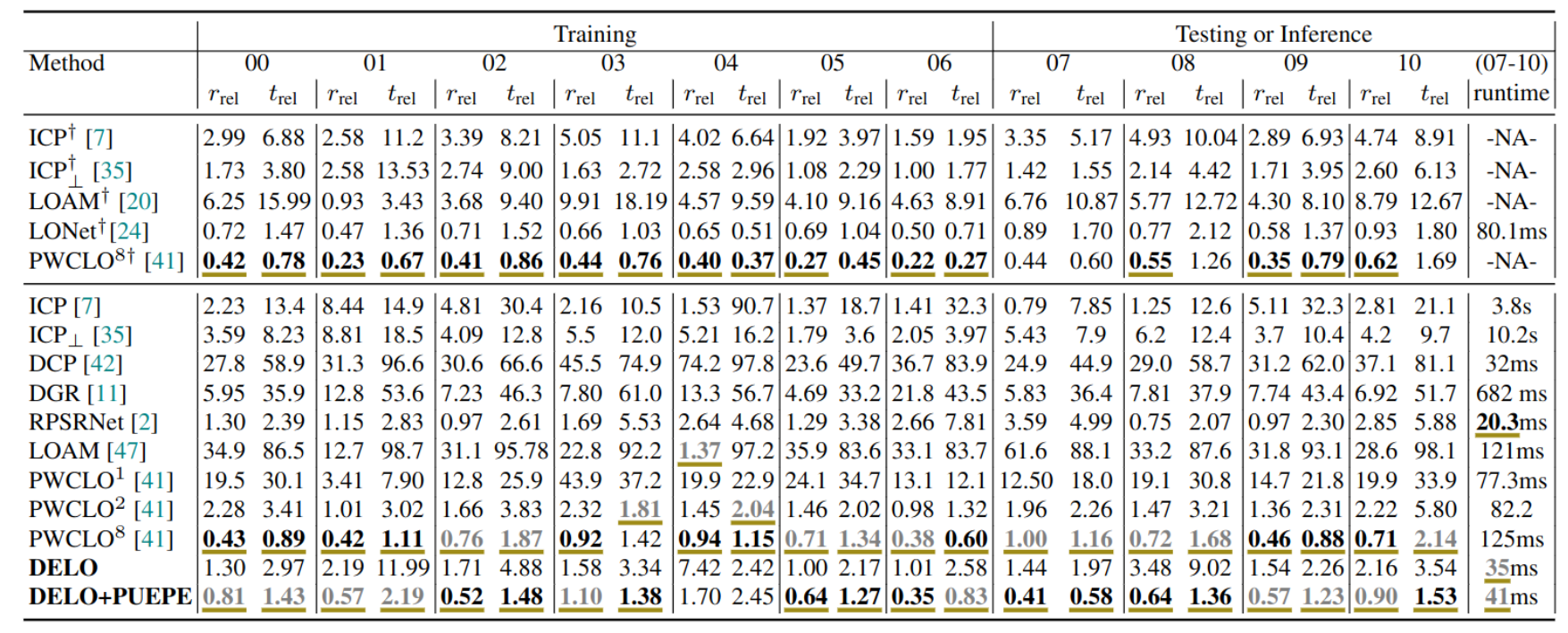
Results of different approaches for LiDAR odomety on KITTI
[18] dataset are
quantified by RRE, RTE metrics. The sequences \(07-10\) that are used for
testing or inference, are not seen during training the network of
the supervised approaches [
24,
41,
42,
2
] and ours.
Black/Gray:
The best and second best entries are underlined and marked in bold black and
gray colors
+: Denotes the error metrics are reported from from PWCLONet [41]
PWCLO\(^{x}\): The superscript \(x\) means \(x * 1024\) number of
input points are used for PWCLONet [41].
This work was partially funded by the project DECODE (01IW21001) of the German Federal Ministry of Education and Research (BMBF)
and by the Luxembourg National Research Fund (FNR) under the project reference C21/IS/15965298/ELITE/Aouada.
If you refer to the results or codes of this work, please cite the following: